
A simple example of how margin call calculation for large amounts of deals can be done with a little help of distributed processing and cloud computing.
Banking Goes Digital – Again!
Middle and back office post-trade bulk processing of financial operations used to be cumbersome matters. Banking was one of the first industries to enter the computer age, investing heavily in robust and lightning-fast sequential computing and relational databases. Eventually this old-school technology became a bottleneck, incompatible with ever-increasing amounts of data to process and the desire to obtain near real-time aggregated information.
Since the beginning of the 21st century, the general focus has moved towards parallel and concurrent computing on loosely structured masses of data. For example, most (if not all) major banks are today very much into Big Data and Cloud Computing. This article describes a hypothetical implementation of financial trade bulk processing in a popular tool for distributed computing – Apache Spark – and deployment in the cloud via a computer cluster provided by Databricks, a company founded by the creators of Spark.
We will generate a sample of one million option deals between 1000 counterparts; obtain underlying volatilities from historical data; valuate all deals on two subsequent dates with the Black-Scholes formula; and sum the change in valuae for the deals to obtain the aggregated margin call for each counterpart. Albeit being a very simplified example, it will somewhat resemble a use case for some derivatives exchange or central counterpart.
The programme is available as open source at Gimlé Digital’s GitHub repository, together with instructions for running it locally in your computer or in Databricks Community Edition (currently free-of-charge).
Divided We Stand, United We Fall
Data processing often benefits from splitting it into different steps. In our particular case, the following division into parts applies:
- Data cleaning: Three file types from two sources are used, namely option contracts and vendor codes from Eurex; and historical equity prices from Nasdaq OMX Nordic. All these are uploaded to Spark data frames with only the relevant columns included. In addition, we only select options on equities traded at the Helsinki stock exchange. The resulting data is then written to temporary files.
- Deal sample: Pseudo-random sampling is used to generate a large amount of deals among counterparts, each of which can appear as either buyer or seller in a deal. Then information about the instrument (i.e. option contract strike, expiry etc.) is added to each deal and the resulting data is written to a file.
- Margin calls: For each one of the underlying equities, the temporary file with historical prices is uploaded to a Spark data frame and the volatility is obtained by computing the standard deviation. Valuation is then calculated for each instrument on two subsequent dates – “yesterday” and “today” – and associated with the corresponding deals. Finally, deal value changes are aggregated by counterpart to obtain “today’s” margin call and the result is written to a file.
Both the temporary and results files are written as legible plain csv files, while in a professional-grade software some binary file format such as Parquet might be preferred. Also, please be aware that the margin calls are obtained through somewhat simplified valuations and without applying thresholds etc.
A Bright Spark in the Cloud
Data upload from files and subsequent cleaning is rather straightforward. Apache Spark can even infer schemas for the data, although explicitly specified schemas often improve performance. We have chosen to import into Spark data frames, to make life easier for anyone who might wish to port the code to Python. For professional-grade programmes and large development teams, type-safe Spark datasets might be preferred. The dataset API is only available to strongly typed languages such as Java and Scala – where data types are verified during compilation – but not in Python, where data types are only verified in runtime when the programme is executed.
In order to obtain a pseudorandom series of deals with different combinations of instruments and buyer and seller counterparts, we have used a Mersenne Twister from the Apache math library. This algorithm is allegedly more robust and sophisticated than the built-in Java/Scala randomizer but even so very fast – it generates our sample of 1,000,000 deals in no time.
The option valuations require a volatility measure for the variations of the underlying equities’ prices. This is easily obtained by applying Apache Spark’s built-in standard deviation function on the historical equity prices for an appropriate time frame, say the last 100 trading days. The valuation also requires the option’s strike and time to expiry, obtained from the instruments file, and the underlying equity’s current price. Lastly, we have chosen to approximate the risk-free interest rate with a constant 1%, whereas a professional-grade software would make use of interest rate curves and interpolations.
Apache Spark allows for “user defined functions”, which takes one or more data columns as arguments instead of individual variable values. This comes in very handy when implementing the Black-Scholes formula. No need for extracting variables from the instrument and prices data frames, just join them together and define Black Scholes as a UDF to be run over the whole data frame at once!
The final aggregation of margin calls rather similar to a summing by group in SQL. We however follow the recommendation to make use of Apache Spark’s “reduceByKey” function instead of a standard “group by” and “sum” statement, for optimization and performance reasons.
To round up, here goes the execution times for the three processes:
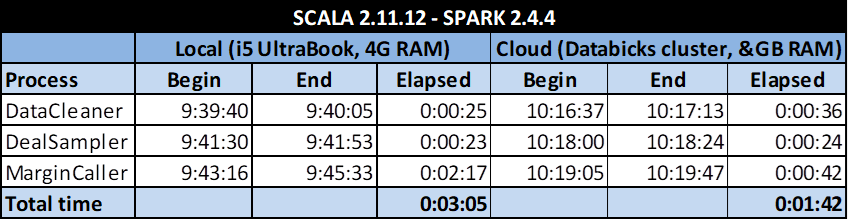
The execution times are similar except for the calculation heavy MarginCaller, for which the Databricks cluster’s better optimization and bigger RAM reduce the time to less than a third.
More Information
Among several guides to Apache Spark, we have found the following one to be particularly useful:
Chambers, B. and Zaharu, M. (2018) Spark: The Definitive Guide. Big data processing made simple. Sebastopol, CA: O’Reilly.
Real market data for options and equities have been employed with the kind permission of Eurex Exchange and Nasdaq OMX Nordic respectively. The files were retrieved from the following web pages:
https://www.eurexchange.com/exchange-en/market-data/statistics/daily-statistics/current-traded-series
https://www.eurexchange.com/exchange-en/products/vendor-product-codes
http://www.nasdaqomxnordic.com/shares/historicalprices
The Scala programme for margin call calculation is available as Open Source code in our GitHub repositories:
https://github.com/GimleDigital/Spark-in-the-Cloud (this version runs in the cloud)
https://github.com/GimleDigital/Scala-Tidbits (this version runs locally in a PC)
- Inicie sesión para enviar comentarios